A Better Way: Co-creation, Not Generation
There's a better way. Not AI that writes your questions. AI that teaches your experts to write sharper ones.
A Better Way: Co-creation, Not Generation
This series started with a simple question. Can AI write your exam questions? It can. But faster is not the same as better.
Then we looked at what happens when you use public chatbots for assessment work. Your content enters training pipelines. Your chat history sits in a sidebar behind one password. Students can inject hidden instructions into submissions. Even self-hosted models carry supply chain risks you can't audit.
Every post pointed to the same conclusion. The problem is not AI. The problem is using tools that were never designed for assessment.
So what does a purpose-built approach actually look like?
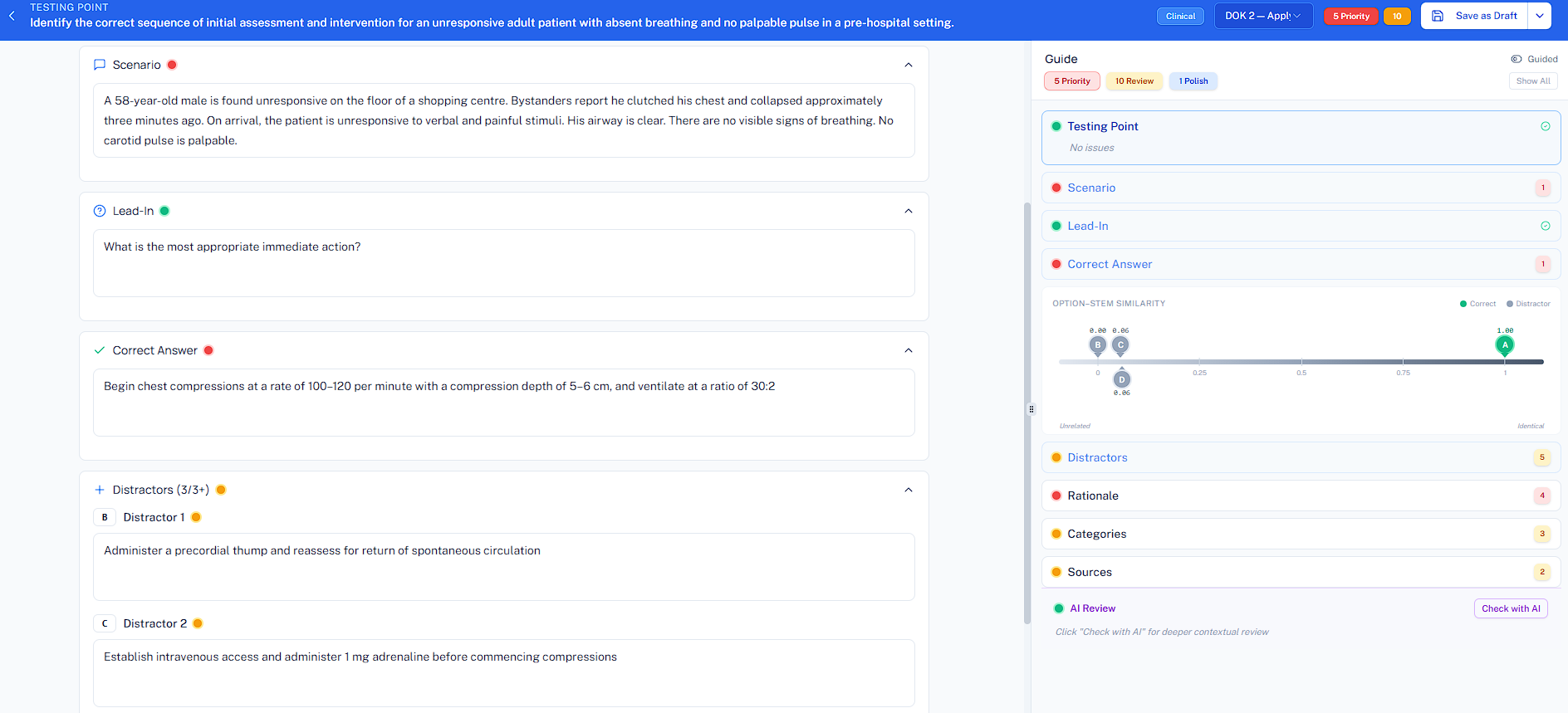
Start With What Matters
The question that matters in assessment is not "can AI generate this?" It is "what must a competent candidate be able to do?"
That is the testing point. And it should come first. Before the scenario. Before the lead-in. Before the options. Before anything else.
Most question writers start with a case they remember. A patient. A situation. The vignette comes first because that is how clinicians think. But without a testing point anchoring the question, the vignette becomes a story, not a tool. The clinical noise overwhelms the clinical signal. The distractors collapse because there is no axis to build them on.
The question was doomed from the first step. Not because the author lacks knowledge. Because nobody asked them what competence they were testing.
The Expert Writes Every Word
AI-generated questions remove the expert from the process. That is the wrong direction. Subject matter experts are the only people who understand the clinical reasoning, the edge cases, the decisions that separate competent practitioners from dangerous ones.
They should write the questions. They just need guidance while they do it.
Not lectures. Not seminars. Not courses on assessment design that happen once a year and are forgotten by the following week. Not red ink from a reviewer weeks after submission. Not their question rewritten by someone else.
Real-time guidance. At the point of authoring. In the moment it matters.
What Cocreation Looks Like
The expert opens the platform. They write a testing point. The platform checks whether it is specific, measurable, and anchored in a competence. If not, it nudges.
They write the lead-in. The platform checks for structural flaws. Cueing language. Negative stems. Vague terms. If something needs attention, the author sees it immediately. Not in a report days later. Now.
They write the options. The platform measures distractor spread. It flags when two options are semantically identical. It shows when one option is obviously shorter than the rest. It highlights when a word in the stem appears in only one option, giving away the answer.
At every step, the expert is in control. The AI watches. It nudges. It asks one question: is this testing what you intended?
The author fixes the issue themselves. They understand why. Next time, they don't make the same mistake. After twenty questions, they write better ones without the platform.
That is the training effect. The platform teaches without teaching.
Why This Is Different
AI generation replaces the expert. Cocreation develops the expert.
AI generation produces questions that look right but may test nothing worth testing. Cocreation ensures the expert's knowledge is captured in questions that are structurally sound, clinically valid, and defensible.
AI generation requires expert review after the fact to catch errors. Cocreation prevents errors at the point of creation.
AI generation treats the question as the output. Cocreation treats the question writer as the investment.
Beyond Question Writing
Writing questions is only part of the assessment lifecycle. Standards need setting. Responses need marking. Results need analysing. Curricula need mapping to the literature. Question banks need sharing securely between institutions.
Each of these stages has the same problem. Spreadsheets. Disconnected tools. No audit trail. No consistency.
CrtQ covers the complete lifecycle. buildCrtQ for guided authoring. setCrtQ for defensible standard setting. assessCrtQ for consistent double marking. statCrtQ for institutional psychometrics. mapCrtQ for literature discovery and curriculum mapping. shareCrtQ for secure question bank sharing.
One platform. One philosophy. AI that guides, not AI that generates.
Built for Assessment
CrtQ does not replace your exam delivery platform. Whatever you use, we sit upstream. We are the intelligence that feeds into it. We don't deliver exams. We make everything that goes into your exam sharper.
Your data stays on EU-hosted infrastructure. Exam content never touches third-party AI models by default. When larger models are used, they operate under zero-retention policies. Every action is logged. Every decision is traceable.
Because assessment content deserves infrastructure built for assessment.
The Philosophy
We change behaviours by nudging, not telling. Our platform has real teeth, but delivered to train, not to lecture.
CrtQ is as much a learning experience as it is a tool. Whether in question writing, standard setting, double marking, or quality assurance, we build competence in the people who assess competence.
Sharper questions. Smarter exams.
This is the final post in a five-part series on AI in assessment. Read the full series: Can AI Write My Exam Questions? / Are You Leaking Exam Questions to AI? / Your Biggest Exam Security Risk Is an Open Browser Tab / Your Students Are Smarter Than Your AI
CrtQ. Sharper questions. Smarter exams. crtq.ai